
I have moved this blog from WordPress to Gatsby.
Please redirect to https://deepstacker.com
I have moved this blog from WordPress to Gatsby.
Please redirect to https://deepstacker.com
I am a huge fan of static web-sites with no fuss, especially in regards to blogs where ease of consuming information is the key. Recently, I have been looking into site generator frameworks to help generate fast and ‘no fuss sites’. One of my consultant buddies recommended me to look into ‘Gatsbyjs’.
So I did! Gatsbyjs is a site generator for React. It provides the ability to generate HTML based upon one or more React templates. What makes Gatsbyjs a bit special, compared to some of the other site generators that I have seen, is the fact that it abstracts away the file system (and other data sources) using a GraphQL.
GraphQL is a query language for API’s. Using GraphQL, one can request what is needed, including references to other resources, by specifying a query containing the types of resources and their relations to other resources. Compared to a REST API, which typically returns a predefined representation, GraphQL allows much more control and is type-safe since the resources are described as types (including references to other types) and not as endpoints .
Gatsby provides the ability to source data from many different sources: file-system, sql, mongodb, rest, etc. into GraphQL. In addition to being sourced, data can also be transformed, e.g. Markdown can be parsed for easier consumption, images can be optimized for the web, etc..
Pages can be generated in many ways. Simplest way is to put a React component into src/pages, which in turn is rendered to HTML and copied to output. Pages can also be generated programmatically, using the createPages API, or by importing a plugin.
Pages can run GraphQL queries that return data previously sourced, allowing the page to be populated with data from the GraphQL server and in turn statically generated and saved in one or more HTML files.
Gatsby also supports Reacts concept of “hydrate”, making it possible to add client-side React to a static generated page and thus provide app like functionality when all JS files have been loaded.
Next step for me is to try to implement this Blog using Gatsbyjs and see how it performs and manages – and if the results are good! Move my blog 100% to Gatsbyjs.
I recently experimented with deep learning algorithms using TensorFlow and Python. A cool use-case I found was to transfer the style of one image onto another image. This can be achieved using a “Neural style transfer” model, which extracts the style of image A, the “semantics” of image B and constructs a new image C with the style of image A and the semantics of image B.
For fun, I did a quick implementation using the Neural style transfer module found here, using Python and Tenserflow:
https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2
Without much tweaking, I got some fun “paintings” as seen below.
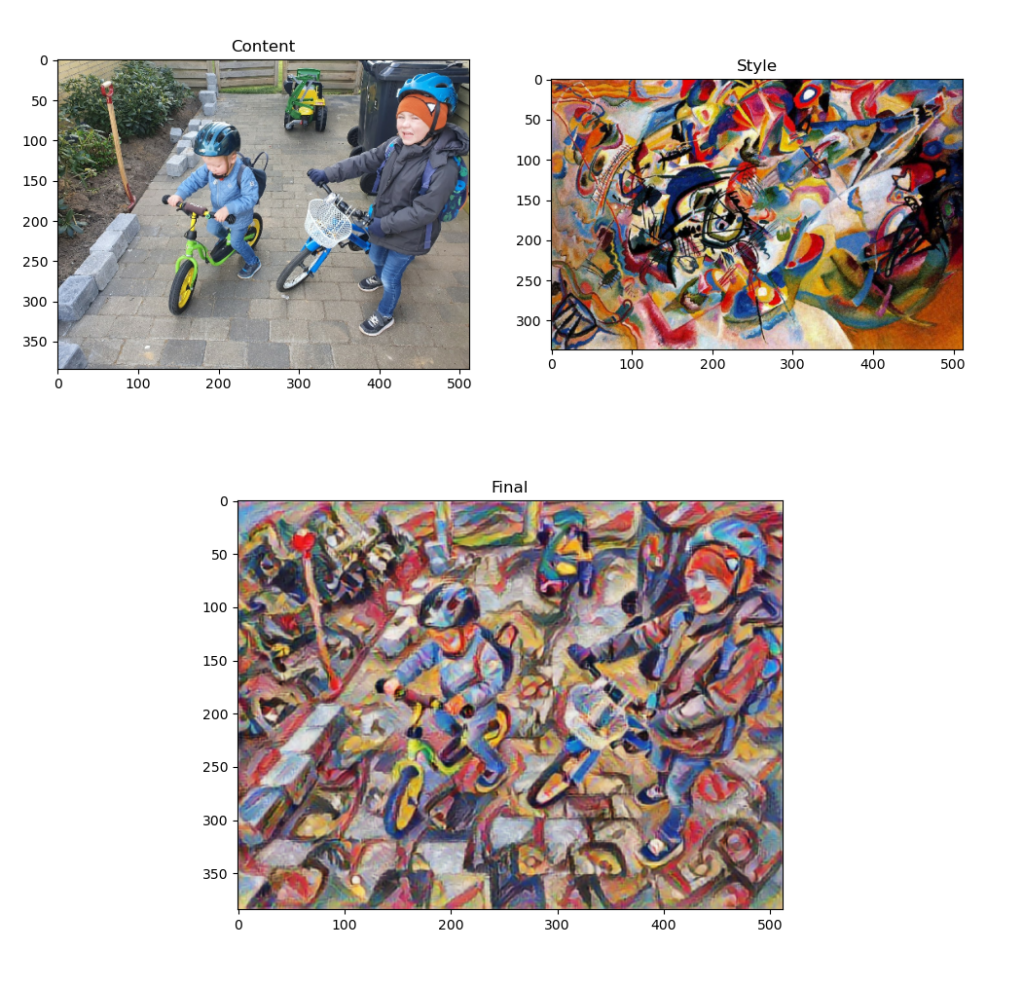




Next step is to port the model to Tensorflow.js and see if I can run the model in the browser and generate similar results!
The cloud project I am currently working had the requirement that we needed to ingest, process, and write several gigs of data in a CosmosDB every 15 min.
For the processing part, we needed something that could scale, since the amount of data was proportional to the number of customers we have hooked up to the system.
Since the project consisted mainly of C# .NET Core developers, the initial processing was done using C# using async operations. This worked well, but was not really scalable – one in the team suggested to use Hangire.io for the processing, which turned out was a great fit for our use case. (Wished it was my idea, but it was not…)
Hangfire is an open source .NET Core library which manages distributed background jobs. It does this by starting a Server in the application where jobs can be submitted. Job types include: fire and forget, delayed jobs, recurring jobs, and continuations.
Hangfire uses a database to ensure information and metadata about jobs are persisted. In our case, we simply use an Azure SQL server. Multiple instances of the application hosting the Hangfire server helps with the processing of the jobs.
This architecture makes it possible to e.g. submit a job for each connected customer, which is processed by one or more nodes. If resources becomes a problem, we horizontal scale up the application to include more instances – which can even be done automatically depending on CPU load or other metric. In our case, we use Kubernetes for that.
What I really like about Hangfire is the fact that one can simply start with one instance of the application hosting the Hangfire server, and scale up later if needed.
Oh! and Hangfire comes with its own integrated dashboard that allows one to see submitted jobs. Neat!
Although we are not yet in production, my gut feeling is good on this one. Highly recommended!
The latest addition to my repository of hobbies is that of 3D printing. December 2018, I bought the FLSun XL Cube 3D printer for my dad as a Christmas gift.
The FLSun XL Cube 3D FDM printer is a Chinese “assemble yourself” kit with a big print volume of 260 × 260 × 350 mm. My father managed to assembly the printer, but he never really got it to print great results.
A month ago I got the printer from him and have been doing tweaks and upgrades here and there. Upgrades include:
The setup looks like this (sitting in my shed):


In addition to the hardware upgrades above, I have done a lot of tweaking of my CURA profile by primarily printing miniatures from D&D and Battletech. (yeah I know, I am a geek)
All in all, with my hardware upgrades and software tweaks, the FLSun XL Cube Printer can do amazing stuff.
I have always been a big fan of THREE.js, a 3D JavaScript library that abstract away some of the complexities of OpenGL. Recently, I tried another library, Babylon.js, written in TypeScript and ofcourse for the browser.
I found Babylon to be on par with THREE on all the areas I needed, except for Camera control where Babylon really shines with it’s built in support for many different types.
Looking at npmjs.com, it’s clear that THREE today the ‘go to library’ when doing 3D in the browser. Currently THREE has 304k downloads a week, while Babylon.js has less than 6k of downloads a week, clearly THREE is more popular.
Size wise, I have not done any test on the produced bundle. I find this absurd in today’s world, where a website does a million AJAX request to load commercials anyway…
The only reason I recommend THREE over Babylon.js is because of it’s popularity on npm. Else, go with any library – they both solve the three-dimensional problem equally well in my opinion.
I had a hard time to reproduce the SameSite cookie issue between multiple Chrome browsers. The reason, as it would seem, was the the Default setting of the SameSite flags are NOT neccesarly the same between Browser instances.

My Chrome on my PC reported “Cookies without SameSite must be secure” to be enabled with default checked, while on my collegues PC, it reported as being disabled with default checked.
This made it impossible for him to reproduce the issue that I had an easy time to reproduce. We had the exact same version of Chrome and were both using Windows 10, although not exact same version of Windows.
Lesson learned: Do not trust the Defaults in Chrome when debugging, enfore the same settings across instances.
In response to my previous post: http://deepstacker.com/2020/03/14/break-on-redirect-in-chrome/
I found the underlying issue to be that of Keycloak not enforcing secure cookies. The Keycloak team fixed this in end of January, but the Keycloak version we were using was from December.
This specific bug was the issue:
I recently had to debug an issue where the browser redirected the user. Debugging this was a pain, since the browser would clear all my views in developer console whenever the redirect happened.
I thought there must be a better way and yes! a bit of googling and I found this Gem:
window.addEventListener("beforeunload", function() { debugger; }, false)
This will break whenever the beforeunload event is executing, which happens right before a redirect.
Simply copy and paste into the console, and you are good to go!
This allowed me to see the exact call-stack leading to the beforeunload event.
In my concrete case the issue was related to a Cookie not being set due to SameSite not being set in a Cookie, which is a requirement by Chrome since version 80.
Introducing automation is something I am extremely keen on. Recently, I have been using Cypress at work, an end-to-end testing framework for browser based applications.
I got the idea that Cypress could be used to do Robot Process Automation (RPA) through the use of GitHub actions. My idea was to:
I look at the bond prices every day on Nasdaq to get an indication on which direction my mortgage is going. A good candidate to automate: let Cypress look at the mortage and send me the result on email such that:
Implementation is super simple, write a test that opens the specific Nasdaq page, selects the element of interest and then emails the element of interest to me using an email client. For my tests, I used mail-slurp since it is free and works well.
The complete cypress code is here:
/// <reference types="cypress" />
import { MailSlurp } from "mailslurp-client";
let last = undefined;
const TO = Cypress.env("TO");
const API_KEY = Cypress.env("API_KEY");
const mailslurp = new MailSlurp({apiKey:API_KEY});
const from = Cypress.env("FROM");
context('Actions', () => {
it("Open Nasdaq", ()=>
{
cy.log(MailSlurp);
cy.visit('http://www.nasdaqomxnordic.com/bonds/denmark/microsite?Instrument=XCSE0%3A5NYK01EA50');
});
it("Find Last", ()=>
{
cy.get(".db-a-lsp").should((e)=>
{
if (e != null)
{
last = e.first().text();
}
});
});
it("Email Last", async ()=>
{
//cy.log(last);
await mailslurp.sendEmail(from,
{
to:[TO],
subject:'0.5% kurs ' + last,
body:last
}
);
});
});
Quick and dirty. Three actions are defined:
Simple as that. Running the “test” does exactly that. To automate, I use GitHub actions to start Cypress on every push but also every day at 09:00 UTC time.
I will definitely try to identify more use cases where this can be applicable in the future.
